
在机器学习中,验证集和测试集有什么区别?
在使用Matlab中神经网络工具箱的时候,经常会很困惑:
我们需要将原始数据集拆分为三份:
训练集、验证集和测试集
但是我也注意到在有些机器学习算法中,数据集往往被拆分为两份:训练集和测试集。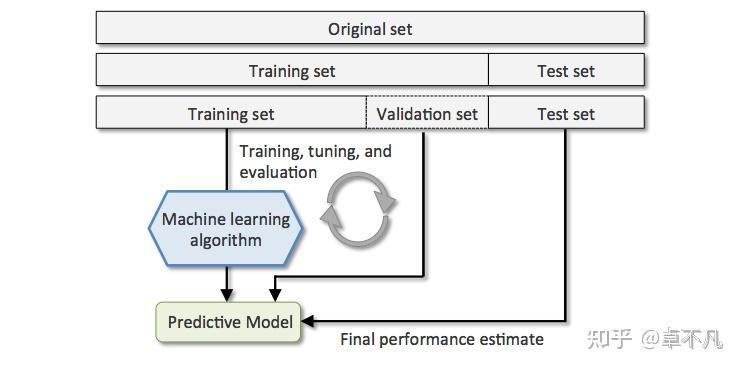
所以我们的问题归纳如下:对于神经网络来说真的需要验证集嘛?验证集是可选的嘛?进一步来说,在机器学习领域验证集和测试集的区别是什么?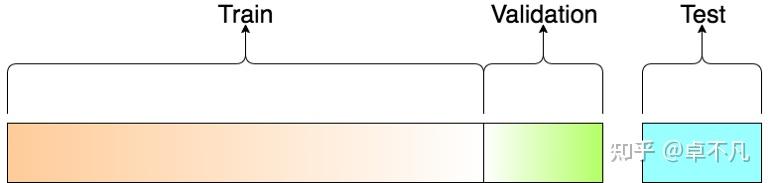
相关定义训练集 (训练阶段) 用于构建我们的模型,我们的模型在训练集上进行学习,通常在这个阶段我们可以有多种方法进行训练验证集 (模型挑选阶段)用于挑选最优模型超参的样本集合:使用验证集可以得到反向传播什么时候结束以及超参怎么设置最合理。主要目的是为了挑选在验证集上表现最好的模型。测试集 (验证阶段 评估泛化误差)在我们挑选好验证集上表现最好的模型之后,用于评估该模型泛化能力的数据集。
一般来说,上述三个数据集的比例为60/20/20.
那么验证集和测试集到底有什么区别?
简单来说,模型在验证集上的表现是有偏估计,虽然训练模型的时候没有用到验证集上的数据,但是我们在挑选模型时,还是间接地泄露了验证集的相关信息:我们让模型知道怎么样的参数设置会让它在该数据集上表现良好或者表现差劲大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。
此时和模型训练挑选过程完全独立的测试集此时就变得更加重要了,它往往代表这模型在真实世界应用场景下模型的泛化表现能力。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
一般来说,在监督学习领域,您需要两种类型的数据集:在第一个数据集中,我们拥有输入数据以及正确/预期的输出;该数据集通常由人工或通过以半自动方式收集而来。但是我们必须在此数据集上获得每个数据的预期输出,因为我们需要它来进行相关的监督学习。我们预期要将模型应用到的数据集大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。在许多情况下,这是我们对模型输出感兴趣的数据,因此我们还没有任何“预期”的输出(即没有真值标注)。
但是在机器学习领域,我们往往这么做:训练阶段: 我们准备标注好的数据,通过输入数据比较预期输出正常训练模型验证阶段:为了估计我们模型的训练效果(这取决于训练数据集的大小、我们想要的预测值等)并估计模型属性(回归模型的平均误差、分类模型的分类误差、 召回率和准确率等)应用阶段:现在,我们将新开发的模型应用于现实世界的数据并获得相应的结果。由于我们通常在此类数据集中没有任何参考真值(否则,为什么需要我们的模型?),我们只能使用验证阶段的结果推测模型输出的质量。
验证阶段通常被细分为两个部分:在第一部分中,我们只需查看模型并使用验证数据来选择性能最佳的方法 (验证集)然后在第二部分数据中评估所选方法的准确性(测试集)。
如果我们不需要从几种模型方法中选择合适的模型,我们可以重新划分我们的数据集合,此时我们理论上只需要有训练集和测试集,而无需对我们的训练模型进行验证。此时二者的划分比例为 70/30。重要的是要记住,不建议跳过测试阶段,因为在交叉验证阶段表现良好的算法并不意味着它真的是最好的,因为算法是根据交叉验证来比较的。在测试阶段,目的是看看我们的最终模型在实际生活中如何处理,所以如果它的性能很差,我们应该从训练阶段开始重复整个过程。


相关文章
-

2022年男篮欧洲杯分组(2022年男篮欧洲杯分组表) - 欧洲杯 - 云起的时候来看看
-
Jeep大切发动机拉缸,维修要13万,专家:密封胶打多了_搜狐汽车_搜狐网
-
[新闻直播间]巴黎系列恐怖袭击事件 德比边境:德方加强巡逻 防止萨拉赫潜入_CCTV节目官网-CCTV-13_央视网(cctv.com)
-
博纳影业25岁“生日”公布五部电影新动向_观众_行动_蛟龙
-
亚洲杯历史历届冠军一览【正文】自1956年以来,亚洲杯足球赛已经成功举办过多届,吸引了众多优秀球队参与。在这篇文章中,我们将一起回顾历届亚洲杯的冠军得主以及他们的辉煌时刻。_伊朗队_比赛_韩国队
-
中甲-陈龙自摆乌龙贵州两失绝佳良机 昆山1-0贵州送对手5连败
-
C罗创纪录,葡萄牙逆转绝杀捷克,一起来看欧洲杯球场——莱比锡红牛竞技场_领域_体育场_图片
-
5万元“转让”10名网络主播?骗局!


![[新闻直播间]巴黎系列恐怖袭击事件 德比边境:德方加强巡逻 防止萨拉赫潜入_CCTV节目官网-CCTV-13_央视网(cctv.com)](https://lallw.com/zb_users/cache/thumbs/9fd6c301d2e59cb69829d4569f70c099-190-120-1.jpg)





评论